گوگل با هوش مصنوعی «پروژهی آسترا» به OpenAI پاسخ میدهد
پاسخ زودهنگام گوگل به ایدهی کامل OpenAI با پروژه آسترا رقم خورد.
تبلیغات


تنها یک روز پس از معرفی GPT-4o توسط OpenAI که ادعا میشود قادر به درک ویدئو و گفتگو در مورد آن است، گوگل از «پروژهی آسترا»، نمونه اولیهی تحقیقاتی خود با قابلیتهای مشابه درک ویدئو، رونمایی کرد. دیمیس حسابیس، مدیرعامل گوگل دیپمایند، این پروژه را روز سهشنبه در سخنرانی کلیدی کنفرانس Google I/O معرفی کرد. آقای Hassabis، پروژهی آسترا را «یک دستیار هوش مصنوعی همهکاره و مفید برای زندگی روزمره» توصیف کرد. در طی نمایش این مدل تحقیقاتی، قابلیتهای خود را با شناسایی اشیایی که صدا تولید میکنند، ارائه تشبیهات خلاقانه، توضیح کد روی مانیتور و پیدا کردن وسایل گمشده به نمایش گذاشت. این دستیار هوش مصنوعی همچنین پتانسیل خود را در دستگاههای پوشیدنی مانند عینکهای هوشمند نشان داد، جایی که میتوانست نمودارها را تحلیل کند، پیشنهاد بهبود ارائه دهد و پاسخهای هوشمندانهای به محرکهای بصری تولید کند.

گوگل میگوید آسترا از دوربین و میکروفون دستگاه کاربر برای ارائه کمک در زندگی روزمره استفاده میکند. آسترا با پردازش و کدگذاری پیوستهی فریمهای ویدئو و ورودی صوتی، یک جدول زمانی از رویدادها ایجاد میکند و برای فراخوانی سریع اطلاعات را ذخیره میکند. این شرکت میگوید این کار به هوش مصنوعی امکان شناسایی اشیاء، پاسخ به سوالات و به خاطر سپردن چیزهایی را میدهد که دیده است، حتی اگر دیگر در قاب دوربین نباشند. در حالی که پروژه آسترا هنوز در مراحل اولیهی توسعه قرار دارد و هیچ برنامهی مشخصی برای عرضهی آن وجود ندارد، گوگل اشاره کرده است که برخی از این قابلیتها ممکن است در اواخر امسال (در قابلیتی به نام «جمینی زنده») به محصولاتی مانند اپلیکیشن جمینی اضافه شود که این موضوع قدمی مهم در توسعهی دستیارهای هوش مصنوعی مفید به شمار میرود. به گفتهی ساندار پیچای، مدیرعامل گوگل، این پروژه تلاشی برای ایجاد یک دستیار هوش مصنوعی با «اختیار عمل» است که میتواند «به پیشبینی شرایط، استدلال و برنامهریزی به جای شما» بپردازد.
در ابتدای سخنرانی، پیچای به نسخهی «بهبودیافته» از مدل ج Gemini 1.5 Pro که در ماه فوریه معرفی شد، اشاره کرد (به طرز عجیبی با همان شمارهی نسخه). این نسخه جدید به پنجرهی زمینهای ۲ میلیون تکهای مجهز خواهد شد که به معنای پردازش تعداد زیادی از اسناد یا بخشهای طولانی ویدئوهای کدگذاریشده به صورت همزمان است. توکنها بخشهای کوچکی از داده هستند که مدلهای زبانی هوش مصنوعی برای پردازش اطلاعات از آنها استفاده میکنند و پنجرهی زمینه، حداکثر تعداد توکنی را که یک مدل هوش مصنوعی میتواند به طور همزمان پردازش کند، تعیین میکند. در حال حاضر، ج Gemini 1.5 Pro حداکثر ۱ میلیون توکن را پردازش میکند (برای مقایسه، پنجرهی GPT-4 Turbo متعلق به OpenAI، ۱۲۸۰۰۰ توکن است).
حال که از توکنها صحبت شد، گوگل اعلام کرد که پنجرهی زمینهی ۱ میلیون تکهای پیشتر اعلامشده برای Gemini 1.5 Pro سرانجام برای مشترکین نسخهی « Gemini پیشرفته» در دسترس قرار خواهد گرفت. پیش از این، این قابلیت تنها از طریق API قابل دسترسی بود. گوگل همچنین از مدل هوش مصنوعی جدیدی به نام « Gemini 1.5 Flash» رونمایی کرد که آن را نسخهای سبکتر، سریعتر و ارزانتر از Gemini 1.5 معرفی میکند. گوگل میگوید: «1.5 Flash جدیدترین عضو خانوادهی مدلهای Gemini و سریعترین مدل قابل دسترس از طریق API است. این مدل برای انجام کارهای حجیم با حجم بالا و فرکانس بالا بهینه شده است.»

ویلسیون، محقق در زمینه هوش مصنوعی نیز در مورد Flash هم نظری داشت: «مدل Gemini Flash جدید امیدوارکننده به نظر میرسد، با هزینهای پایینتر تا سقف 2 میلیون توکن را در اختیار کاربر قرار میدهد.» هزینه Flash برای درخواستهای تا ۱۲۸ هزار توکن، ۳۵ سنت به ازای هر یک میلیون توکن و برای درخواستهای بلندتر از ۱۲۸ هزار توکن، ۷۰ سنت به ازای هر یک میلیون توکن است. این رقم یک دهم قیمت 1.5 Pro است.
ویلسیون، پژوهشگر سرشناس در این باره گفت: «۳۵ سنت به ازای هر یک میلیون توکن! به نظر من، این مهمترین خبر امروز است.»گوگل همچنین از «جواهرها» (Gems) رونمایی کرد، که به نظر میرسد پاسخ این شرکت به «GPT» های OpenAI باشد. جواهرها نقشهای سفارشیشدهای برای چتبات Gemini گوگل هستند که به شما اجازه میدهند تا Gemini را به روشهای مختلف شخصیسازی کنید و نقشی را که برای آن تعریف میکنید، بازی کند. گوگل به عنوان مثالهایی از جواهرهای بالقوه به «همراه باشگاه، سرآشپز کمکی، شریک برنامهنویسی یا راهنمای نویسندگی خلاق» اشاره میکند.
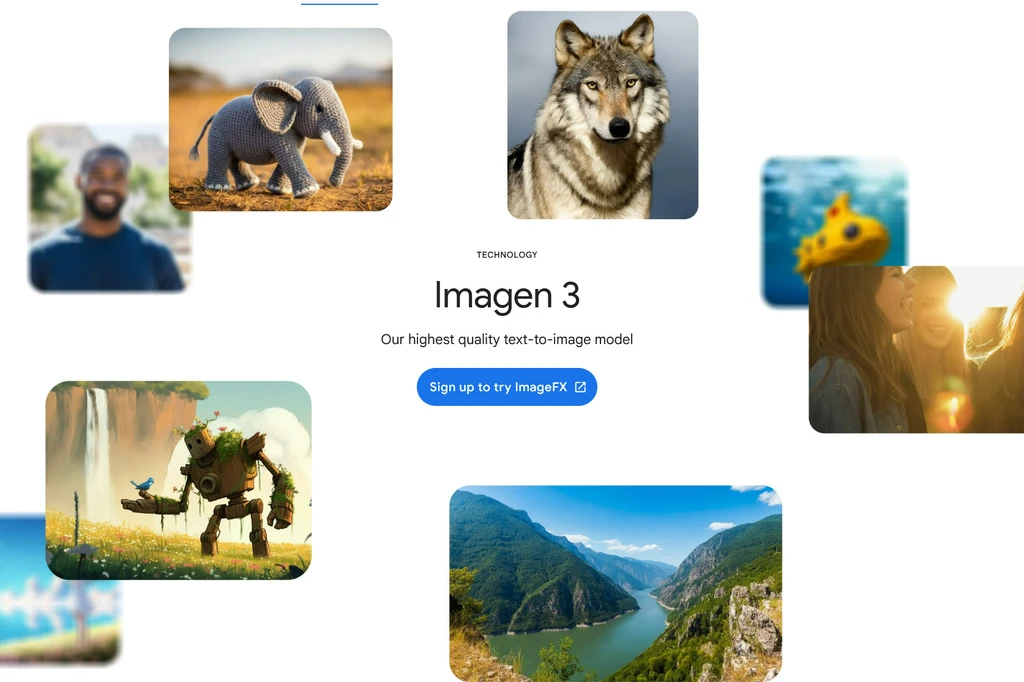
همچنین در سخنرانی Google I/O در روز سهشنبه، گوگل چندین مدل هوش مصنوعی تولیدکنندهی جدید برای ایجاد تصاویر، صدا و ویدئو معرفی کرد. «Imagen 3» جدیدترین مدل در سری مدلهای سنتز تصویر گوگل است که به گفتهی گوگل، «باکیفیتترین مدل تبدیل متن به تصویر ماست که قادر به تولید تصاویری با جزئیات بهتر، نورپردازی غنیتر و مصنوعات مزاحم کمتر نسبت به مدلهای قبلی ما است.» این شرکت همچنین از Music AI Sandbox خود رونمایی کرد که گوگل آن را «مجموعهای از ابزارهای هوش مصنوعی برای متحول کردن نحوهی خلق موسیقی» مینامد.
این ابزار با ترکیب پروژهی موسیقی یوتیوب و مولد موسیقی هوش مصنوعی لایرا، امکاناتی را برای موزیسینها فراهم میکند. همچنین گوگل از Google Veo رونمایی کرد که یک مولد متن به ویدیئو است که ویدیوهای 1080p را بر اساس درخواستهای متنی و با کیفیتی مشابه با Sora شرکت OpenAI تولید میکند. گوگل میگوید با همکاری بازیگر دونالد گلاور در حال ساخت یک فیلم نمایشی تولیدشده توسط هوش مصنوعی است که به زودی منتشر خواهد شد. Veo اولین مولد ویدیویی هوش مصنوعی گوگل نیست، اما به نظر میرسد تا به امروز توانمندترین آنها باشد.
گوگل میگوید ابزارهای خلاقانهی هوش مصنوعی جدید آنها از امروز تنها برای گروه منتخب سازندگان در یک پیشنمایش خصوصی در دسترس است، اما هماکنون امکان ثبتنام در لیست انتظار وجود دارد.


